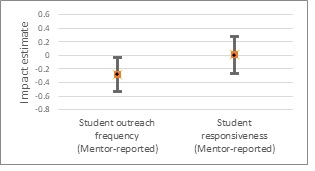
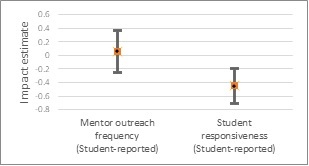
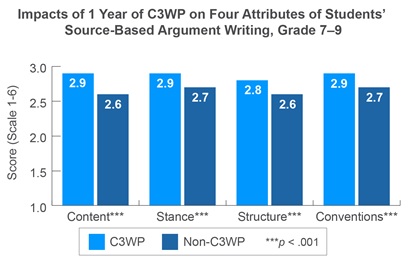
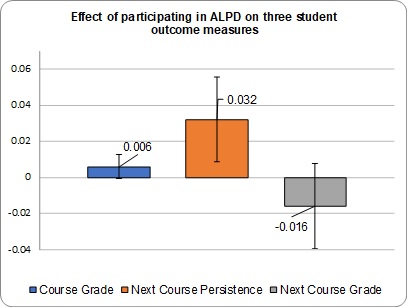
When randomized control trials are not possible, quasi-experimental methods like Regression Discontinuity and Difference-in-Difference (DiD) often represent the best alternatives for high quality evaluation. Researchers using such methods frequently conduct exhaustive robustness checks to make sure the assumptions of the model are met, and that results aren’t sensitive to specific choices made in the analysis process. However, often there is less thought applied to how the outcomes for many quasi-experimental studies are created. For example, in studies that rely on survey data, scores may be created by adding up the item responses to produce total scores, or achievement tests may rely on scores produced by test vendors. In this study, several item response theory (IRT) models specific to the DiD design are presented to see if they improve on simpler scoring approaches in terms of the bias and statistical significance of impact estimates.
Why might using a simple scoring approach do harm in the quasi-experimental/DiD context?
While most researchers are aware that measurement error can impact the precision of treatment effect estimates, they may be less aware that measurement model misspecification can introduce bias into scores and, thereby, treatment effect estimates. Total/sum scores do not technically involve a measurement model, and therefore may seem almost free of assumptions. But in fact, they resemble a constrained measurement model that oftentimes makes unsupported assumptions, including that all items should be given the same weight when producing a score. For instance, on a depression survey, total scores would assume that items asking about trouble sleeping and self-harm should get the same weight in the score. Giving all items the same weight can bias scores. For example, if patterns of responses differ between treated and control groups, faulty total score assumptions could bias treatment effect estimates and mute variability in the outcome researchers wish to quantify.
What decisions involved in more sophisticated scoring approaches impact treatment estimates?